
РАСШИРЕННЫЙ КОММЕНТАРИй
| ТОМ 2. ВЫПУСК 7 (12)
Между алгоритмическим воображаемым и «большими данными»

Колпинец Екатерина Владимировна
приглашенный преподаватель, аспирант НИУ ВШЭ, школа философии и культурологии
Алгоритмическое воображаемое и алгоритмические сплетни
В социальных сетях последних пяти лет, в особенности в Instagram и Facebook, наиболее интересным мне видится конфликт между так называемыми большими данными и пользовательскими аффектами. В 2017 году в своей статье «The algorithmic imaginary: exploring the ordinary affects of Facebook algorithms» [1] датская исследовательница медиа Тина Бухер ввела термин «алгоритмическое воображаемое». Используя феноменологический и этнографический подходы, она пришла к выводу, что понимание пользователями алгоритмов лежит в области домыслов и аффектов, а не в области знаний или логики. У людей нет ясного понимания работы алгоритмов, тем не менее некоторые из них пытаются понять их устройство, исходя из личного опыта. Алгоритмическое воображаемое — пространство, где встречаются люди и алгоритмы. Бухер интересует, в каких ситуациях люди узнают об алгоритмах, как они их понимают и воспринимают, учитывая невидимую природу последних.
25 респондентов, которых Бухер опросила в ходе этнографического исследования, рассказывали, как пытались подстроить под себя алгоритмы, а также какие чувства испытывали, сталкиваясь с алгоритмами Facebook, как пытались понять, почему видят в ленте рекламу, не соответствующую их интересам, почему посты одних друзей демонстрируются каждый день, а других людей алгоритмическая лента старательно скрывает. При этом опыт встречи людей с алгоритмами не был воображаемым. Напротив, он был в высшей степени реальным, порождал у людей реальные тоску, тревогу, радость, гнев, отчаяние.
Представления о работе алгоритмов сильно различались и зависели от индивидуального опыта и пользовательских практик: делали ли люди посты или только читали и лайкали чужие посты, листали ленту с компьютера или с телефона, сколько раз в день и на какое время заходили в соцсети и т. д. То есть принципиально важен контекст использования: алгоритмы и их работу, по мнению Бухер, невозможно понять в отрыве от контекста.
Схожий взгляд на алгоритмы предлагает британская исследовательница Софи Бишоп. В статье «Managing visibility on YouTube through algorithmic gossip» [2] она ввела термин «алгоритмические сплетни», основываясь на глубинных интервью с бьюти-блогерами. Он означает способы обхода алгоритмов YouTube, основанные на обмене блогеров личным опытом взаимодействия с платформой. С помощью взаимных лайков, репостов и других ухищрений блогеры пытаются обойти систему, которая скрывает их видео и посты из ленты выдачи. Бишоп делает акцент на том, что алгоритмы, их скрытая, часто непонятная для пользователей природа, порождают новые коллективные сетевые практики.
В разговоре об алгоритмах, их влиянии на коллективное и индивидуальное восприятие соцсетей, на мой взгляд, важен конфликт очищенных от контекста больших данных, на которые так любят ссылаться маркетологи и аналитики, и пользовательских практик, пронизанных аффектами и догадками. Даже имея большие данные, например, подробную статистику пользователей с учетом возраста, гендера, территориальной принадлежности пользователей, исследователи и маркетологи часто не могут правильно интерпретировать эти данные, понять, о чем они говорят и что значат. Точно так же, как не могут приблизиться к пониманию, на что влияют алгоритмы и в чем выражается это влияние.
Когда какой-нибудь коуч или «эксперт», рекламируя свой курс, говорит: «Я расскажу вам, как работают алгоритмы соцсетей и как заставить их работать на себя», — это повод насторожиться. Если бы алгоритм Facebook было так легко раскусить, компания Цукерберга не стоила бы триллионы долларов. Алгоритм, который мы не видим и принципы работы которого нам неизвестны, такая же собственность Facebook, как недвижимость, компьютеры, копировальные машины, сервера. Поэтому любая серьезная попытка докопаться до сути работы алгоритма может быть расценена как посягательство на собственность Facebook.
В 2021 году проект немецких исследователей AlgorithmWatch решил прекратить работу по изучению алгоритмов Instagram: представители Facebook попросили их о встрече, где заявили, что действия AlgorithmWatch нарушают условия обслуживания соцсети по сбору данных. Также Facebook сообщил, что проект собирал данные без согласия пользователей. Несмотря на объяснения исследователей, что они собирали данные только от тех пользователей, которые давали им доступ к своей ленте, проект было решено закрыть, чтобы не столкнуться с иском от компании [3].

О связи рейтингов и доверия
Практически любой разговор об алгоритмах рано или поздно выруливает на тему видимости в социальных сетях и, в конечном счете, на тему влияния. Рейтинги, всевозможные «топы» и списки популярных и самых влиятельных блогеров глубоко проникли в повседневную цифровую культуру, при этом мало кто задается вопросом, в чем, собственно, это влияние заключается.
Большую роль в этом сыграл скандал 2018 года вокруг Cambridge Analytica и последовавшая моральная паника относительно «фейковых новостей». В марте 2018 года стало известно, что британская компания Cambridge Analytica собрала личные данные в общей сложности 87 млн пользователей через свое приложение в Facebook, после чего использовала их в политических целях, в частности во время президентской кампании в США и референдума о выходе Великобритании из Евросоюза. Расследование, проведенное Британским комиссариатом по информации, выявило, что с 2007 по 2014 год Facebook недобросовестно обрабатывал персональные данные пользователей, передавая их разработчикам мобильных приложений, а также не обеспокоился о получении «достаточно ясного информированного согласия» тех, чьи данные были собраны.
Принципиально важный момент этой истории: у пользователей социальных сетей, во всяком случае у самой прогрессивной ее части, появилось понимание, что социальные сети превращают поведение аудитории, ее реакции и эмоции в ценные данные. Все, что вы загружаете в Instagram и Facebook, принадлежит платформам. В этом отношении пользователи заняты сверхотчужденным трудом, а платформы находятся в суперпривилегированной позиции, даже если у вас миллион подписчиков. Решение об удалении контента принимается в одностороннем порядке: невидимые модераторы могут удалять ваши фотографии, блокировать ваш аккаунт, демонетизировать видео, а вы как пользователь не можете повлиять на принятие решений. Глобальные индустрии, построенные на показателях внимания, проектируются не одним человеком, а создаются конкурирующими потребностями пользователей, создателей контента, рекламодателей и инвесторов.
Даже понимая, что «топовость» того или иного сетевого персонажа — это производная работы непрозрачных алгоритмов и волюнтаристских решений платформы, мы все равно по умолчанию воспринимаем их как авторитетов, людей, имеющих большое влияние. Здесь интересен вопрос, как это влияние соотносится с доверием.
Рисунок 1. Скажите, пожалуйста, насколько Вы доверяете представителям следующих профессий? Оцените по пятибалльной шкале, где 1 — «совершенно не доверяю», 5 — «полностью доверяю» (ноябрь 2020) [4]
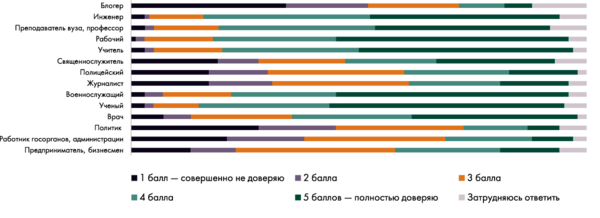
Люди блогерам как раз не доверяют, и это показывают опросы, в том числе ВЦИОМ (рис. 1). Речь точнее будет вести не о доверии и даже не о популярности. В последние пять-семь лет исследователи селебрити и сетевой культуры употребляют не слова «популярность» или «известность», а «видимость». Этот термин предложила австралийский антрополог Кристал Абидин. Интернет-звезда, блогер — человек с высокой видимостью. Это значит, что вы заходите на YouTube и куда бы вы ни нажали, из какой бы точки вы это ни делали, вы с большой долей вероятности увидите там Дудя, Ивлееву или Влада Бумагу. То, что человек хорошо видим или стал мемом, не значит, что люди доверяют ему.
Одна из больших проблем изучения влияния блогеров и доверия к ним аудитории заключается в том, что подобные исследования по большей части инициированы маркетинговыми компаниями и связаны с изучением потребительского поведения. Главный вопрос здесь — дойдет ли товар до конечного потребителя и эффективна ли реклама у блогеров. О доверии и авторитете речь в подобных случаях не идет.
Популярность зачастую не коррелирует с доверием. Парадокс в том, что всплеск критики и хейта только повышает позицию блогера в выдаче, люди могут быть настроены резко негативно, но при этом не отписываются от блогера. Наоборот, число подписчиков только растет. Весьма показательна в отношении института репутации история Регины Тодоренко, которая во время прямого эфира для одного глянцевого журнала стала оправдывать домашнее насилие, обратившись к зрительницам: «А что ты сделала, чтобы он тебя не бил?». После волны критики в соцсетях, расторжения нескольких рекламных контрактов и лишения ее премии «Женщина года Glamour» она написала покаянный пост в Instagram и сняла фильм «А что я сделала, чтобы помочь?», пожертвовав в центр «Насилию.нет» 2 млн рублей. Критики было очень много, но от блогера практически никто не отписался, в итоге все быстро забылось. Еще один яркий пример — блогер-миллионник Екатерина Диденко («Аптечный ревизорро»), чей муж и двое друзей погибли в бассейне с сухим льдом в феврале 2020 года. Массовая травля началась после того, как Диденко снимала Instagram-stories во время похорон мужа, через неделю пошла на шоу «Пусть говорят», а через несколько месяцев сделала операцию по увеличению груди и представила подписчикам нового избранника. Несмотря на продолжительную волну хейта, с момента трагедии с сухим льдом на нее подписалось 400 тысяч человек.
Люди часто не могут рационально обосновать свои симпатии и антипатии к кому-то. В подобных случаях не стоит недооценивать силу привычки — раньше утром включали радиоприемник, слушали государственный гимн, а вечером смотрели программу «Вести». Теперь листают stories, залипают в Facebook, едят под видео на YouTube. Есть иллюзия, что мы сами это выбрали, но это, мягко говоря, не соответствует действительности. Человеку все сложнее быть выключенным из информационного потока, есть страх остаться за бортом, упустить что-то важное, что также сильно влияет на привычки потребления контента.
Как правильно заметила Бухер, когда дело касается соцсетей, решения принимаются иррационально. Это стоит учитывать, когда кто-то в очередной раз пытается рационализировать массовое стихийное выражение эмоций. Исследовательница, цифровой этнограф Аннет Маркхэм [5] пользуется таким методом — она просит студентов показать приложения в своих телефонах и рассказать, чем они пользуются в течение дня, куда уходит их время. Нередко студенты оказываются в тупике, поскольку не могут объяснить, почему они залипают с утра до вечера, что конкретно их затягивает, привлекает.
Любой рейтинг в социальных сетях — очень большая условность. Если взять конкретных людей из числа опрошенных и задать вопрос, кому и почему они доверяют, почему они лайкают одновременно, например, видео Никиты Михалкова и посты Навального, им будет сложно ответить. Опрос людей о том, кого они считают авторитетом и почему, может дать куда более интересный результат, чем большие данные (которые, к слову, тоже метафора, как и алгоритмическое воображаемое), рейтинги и списки лучших из лучших.
Пользователи оказываются в ситуации, где, с одной стороны, устройство алгоритма остается скрытым от них, а с другой — иррациональность поведения самих пользователей только возрастает. И самое неблагодарное дело в данной ситуации — думать об алгоритмах и аффектах как о линейных процессах, подвластных логике прогресса. Пользовательское понимание не перестает быть фрагментарным и ситуативным.
[1] Bucher T. (2017) The Algorithmic Imaginary: Exploring the Ordinary Affects of Facebook Algorithms. Information. Communication & Society. Vol. 20. No. 1. P. 30—44. https://www.doi.org/10.1080/1369118X.2016.1154086.
[2] Bishop S. (2019) Managing Visibility on YouTube Through Algorithmic Gossip. New Media & Society. Vol. 21. No. 11—12. P. 2589—2606. https://www.doi.org/10.1177/1461444819854731.
[3] Исследователи алгоритмов Instagram закрыли проект после обвинений Facebook в нарушении условий сбора данных // TJournal. 13.08.2021. URL: https://tjournal.ru/news/423933-issledovateli-algoritmov-instagram-zakryli-proekt-posle-obvineniy-facebook-v-narushenii-usloviy-sbora-dannyh.
[4] Опубликовано на сайте ВЦИОМ в базе данных архива «Спутник». URL: https://bd.wciom.ru/baza_rezultatov_sputnik/.
[5] Этнография в цифровую эпоху: от полей к потокам, от описаний к воздействию. Часть I // Системный блок. 17.05.2019. URL: https://sysblok.ru/society/ethnography-in-the-digital-internet-era-1/.


Мы в соцсетях: