
РАСШИРЕННЫЙ КОММЕНТАРИЙ
| ТОМ 4. ВЫПУСК 7—8 (27)
Нейросети в работе исследователя

Антон Малышев
маркетолог, веб-аналитик, консультант
В качестве краткого эпиграфа к этой статье об актуальности и темпах развития технологий хочется привести наглядный пример. Уже после того, как эта статья была написана, вышло большое обновление одного из часто используемых инструментов, которое сильно расширило возможности исследователей. Мне пришло в голову несколько идей, и я сразу же внедрил их на боевых проектах, после чего статью пришлось переписывать. Результатами поделюсь в финальной части, надеюсь, читателю-энтузиасту будет полезно. Тех же, кому невтерпеж или срочно нужно решать рабочие задачи, приглашаю сразу к финалу статьи.
Коротко обо мне, авторе этого текста. Антон Малышев, 31 год, 11 лет работаю в маркетинге и аналитике, управляю агентством performance-маркетинга. Среди прочего часто занимаюсь как классическими маркетинговыми исследованиями (полевыми, цифровыми), так и более современными методами обработки данных клиентов — кластерный анализ, различные методы машинного обучения и т. д.
Думаю, нет нужды объяснять, что чем больше данных мы собираем, тем больше инсайтов, способных оказать импакт на наши бизнес-процессы, мы обнаруживаем. Однако в процессе сбора и анализа необходимо учитывать множество факторов — актуальность данных, их консистентность; важно понимать, где на показатели можно опереться, а где появляются статистические выбросы за пределами доверительных интервалов, которые ломают модели и вводят в заблуждение исследователей. Поэтому, несмотря на дикое желание переложить рутинные задачи обработки данных на различные модели и нейросети, важно помнить, что они по-прежнему требуют наблюдения и контроля со стороны исследователей.
Первое, что приходит в голову при виде возможностей нейросетей, это автоматизация рутины. Выявление шаблонов и корреляций, которые могут быть не видны при ручном анализе. Более того, нейросети могут расширять возможности исследователей, создавая новые методы анализа данных, такие как предсказательное моделирование или генерация новых данных на основе существующих. Однако, когда я приступил к решению конкретных задач, понял, что реально применимых в работе инструментов не так уж и много, и полез изучать чужой опыт.
Нейросети: задачи и ниши
Нейросети уже работают автономно во многих областях, от беспилотных автомобилей до рекомендательных систем. В социальных исследованиях, например, нейросети используются для автоматического анализа социальных медиа, определения общественного мнения или даже предсказания политических выборов. Они также играют важную роль в автоматическом анализе текста, обрабатывая большие объемы данных за значительно меньшее время, чем это может сделать человек. Звучит хайпово? Но остается уделом крупных корпораций и дорогих b2b-продуктов.
На самом деле нейросети используются достаточно давно, их существует множество типов, и во многих привычных нам продуктах будут присутствовать модели машинного обучения или нейросети. Поисковые системы, социальные сети, рекламные системы, рекомендательные алгоритмы маркетплейсов — они везде. Только как к ним подступиться, если ты не OpenAI, Microsoft или Google? Учиться собирать модели вручную. Поэтому пришлось освоить Python и ряд профильных библиотек — Pandas, NumPy, Keras, TensorFlow и прочие. Ниже приведу краткий список навыков, которые не будут лишними при работе с нейросетями.
Необходимые навыки и инструменты для исследователей в эпоху AI
1) Основы программирования и работы с данными. Для успешной работы с AI исследователям необходимо знание языков программирования, таких как Python или R, а также опыт работы с библиотеками для машинного обучения и обработки данных, например TensorFlow, Keras или Pandas. Эти скиллы помогут вам самостоятельно готовить и анализировать данные, а также модифицировать и настраивать модели AI.
2) Понимание основ машинного обучения и нейросетей. Хотя для использования AI-инструментов не всегда требуется глубокое понимание того, как они работают, знание базовых принципов машинного обучения и нейросетей является важным активом. Это поможет вам быстрее ориентироваться в результатах, полученных при помощи нейросетей, и лучше понимать ограничения этих инструментов.
3) Навыки работы с большими данными. С появлением больших данных нам все чаще приходится работать с огромными массивами информации. Опыт работы с инструментами для обработки и анализа больших данных, такими как SQL во всех его проявлениях, Hadoop или Spark, Clickhouse от Яндекса, а также понимание принципов работы баз данных может быть очень полезным.
4) Критическое мышление и навыки интерпретации результатов AI. Вы должны понимать ограничения и потенциальные ошибки AI, а также учитывать эти факторы при принятии решений на основе результатов его работы.
5) Цифровая грамотность. Как ни прискорбно, я часто встречаю у начинающих специалистов отсутствие навыков эффективного использования компьютера и базового ПО, начиная от хоткеев и Excel и заканчивая неумением разобраться в новом софте. Исследователям необходимо быть в состоянии эффективно использовать различные цифровые инструменты и платформы, а также уметь работать с большими наборами данных.
6) Навыки визуализации данных. Об это я отдельно споткнулся, изучая matplotlib, а также регулярно защищая аналитические проекты перед людьми, которые не понимают графики. Да, можно нарисовать классный scatter plot c линиями тренда, доверительным интервалом и 6 sigma на подложке, только принимающая сторона поймет в нем примерно ничего. Иногда лучше обойтись примитивным пайчартом или спарклайном с качественно разжеванной легендой. Способность эффективно визуализировать и представлять данные является сегодня ключевым навыком и помогает лучше донести результаты до лиц, принимающих решения.
Рис. 1. Слабо сходу понять, что происходит на этом графике?
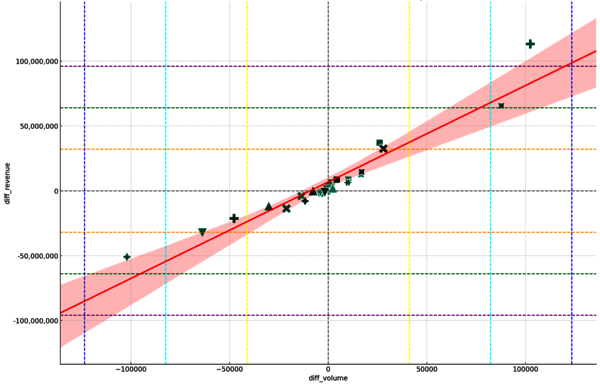
7) Навыки общения и представления результатов. Пункт, вытекающий из предыдущего. Мало найти крутые инсайты, их нужно донести и предложить решения на их основе, после чего аргументировать и защитить. Генеративные нейросети, конечно, можно попросить объяснить сложные идеи простым языком, но вам все равно пригодится умение убедительно аргументировать свою точку зрения и понадобятся навыки презентации ― эти soft skills AI заменить пока не готов.
Окей, гугл, я все это умею. Что дальше? А дальше мы сталкиваемся с ограничениями платформ и моделей, а также рисками, которые из этого вытекают. Я оставлю этические вопросы, связанные с приватностью данных и использованием публичных платформ (таких как Google Colab, Hugging Face и других), и постараюсь сосредоточиться на сложностях, которые возникают каждый день при подготовке и обработке данных:
1) Ограничения AI в понимании контекста. AI-системы по-прежнему испытывают трудности с пониманием контекста, метафор и двусмысленности, которыми обычно наполнены человеческий язык и общение. Даже самые продвинутые AI, такие как GPT-4, не могут полностью понимать контекст и подтекст человеческого общения. Это означает, что результаты анализа текста AI могут быть неточными или вводящими в заблуждение, если они не проверяются и не интерпретируются квалифицированными исследователями.
2) Большие данные — не всегда маркер качества. Несмотря на способность AI обрабатывать огромные объемы данных, большое количество информации не всегда означает высокое качество выводов. AI-системы могут найти шаблоны и корреляции в данных, но они не могут определить причинно-следственные связи или учесть скрытые переменные. Кроме того, AI может «переобучиться» на основе аномальных данных, что приводит к неточным или ошибочным выводам.
3) Недостатки в интерпретируемости моделей AI. Многие нейросетевые модели, особенно глубокие нейросети, являются «черными ящиками». Это означает, что понять, как именно они пришли к определенному выводу или предсказанию, трудно, если не невозможно. Поэтому их выводы бывает сложно интерпретировать без знания того, как работают эти модели. Это может стать проблемой, особенно в социальных исследованиях, где важно понимать не только что происходит, но и почему это происходит.
4) Зависимость от качества исходных данных. Качество результатов, которые дает AI, во многом зависит от качества входных данных. Если исходные данные смещены или неполны, AI может воспроизводить и усиливать эти смещения в своих выводах. Это означает, что исследователи должны тщательно подходить к выбору и обработке данных, которые они используют для обучения и тестирования своих моделей AI.
Переходим к практике
Теперь мы все умеем, качественно подготовили данные. Как же воспользоваться существующими инструментами? Первое, что мы начали внедрять в анализе данных, — это модели машинного обучения. Регрессионный анализ, кластерный анализ, классификация результатов опросов, но это все находится немного за рамками данной статьи.
Идеи для GPT
С появлением генеративных нейросетей возникла возможность немного разгрузить линейных специалистов, занятых в исследованиях — ChatGPT помогал нам формировать опросники, рассчитывать выборки и доверительные интервалы, строить гипотезы на основании полученных данных, описывать результаты анализа.
Он помогал нам писать SQL-запросы к базам данных, писать код для построения необходимых графиков, программировать статистические формулы кодом для применения их к данным проекта.
Основной минус заключался в том, что туда невозможно было загрузить сами данные или графики, а затем попросить описать их или проанализировать. Но все изменилось с приходом функции Code Interpreter в четвертой модели от OpenAI.
Новые горизонты
Разберем на примере. Возьмем типовой запрос: сколько нужно совершить показов рекламы и в каких источниках, прежде чем новый пользователь совершит конверсионное действие, например подписку или покупку?
Рис. 2. Пример данных Google Analytics
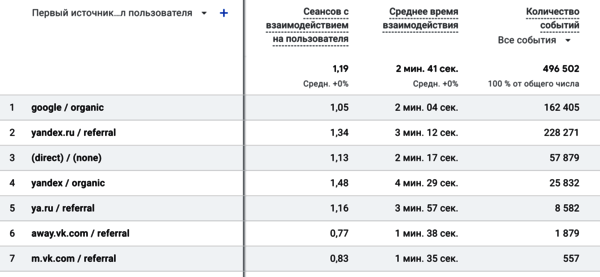
У нас есть данные из Google Analytics, 500 000 строк с данными о событиях на сайте за месяц. Благо, в GA есть (был из коробки без донастройки, до выхода GA4) инструмент «Пути конверсии», где мы можем прямо в интерфейсе аналитической системы посмотреть наиболее часто встречающиеся последовательности заходов на сайт из различных каналов, приводящие к конверсионному действию.
Рис. 3. Пример инструмента «Пути конверсии»
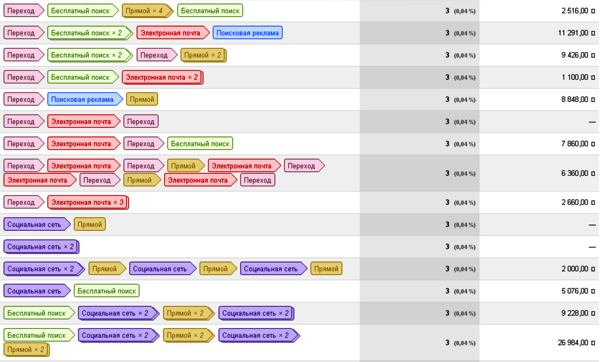
Очевидно, что графический интерфейс не позволяет массово обработать данные, а собирать вручную результаты из полумиллиона записей можно до конца света. Поэтому мы выгружаем данные в CSV и идем общаться с ChatGPT.
Именно тут нам и помогает новый модный интерпретатор кода. Лайфхак следующий: GPT-4 понимает различные форматы кода и входных данных, однако не умеет работать с базами данных или документами формата Excel. Но прекрасно справляется с CSV, XML, JSON и другими привычными для программистов форматами хранения данных. Хитрость заключается в том, чтобы попросить ChatGPT перегнать эти данные, к примеру, в Pandas DataFrame, после чего работать с ними дальше, как с обычным кодом — только не программировать вручную, а просто давать задачу генеративной нейросети.
Какие промпты (запросы) можно сделать к модели в этом случае?
- Опиши модель данных, которые ты видишь в таблице.
- Установи, есть ли корреляция между столбцом ‘A’ и столбцом ‘B’ согласно коэффициенту Пирсона.
- Построй диаграмму (указать вид — scatter plot, pie chart, sparkline и т. д.) для столбцов ‘C’ и ‘D’ в разрезе уникальных значений столбца ‘A’.
- Как можно охарактеризовать данные в таблице, и что необходимо проанализировать, чтобы сделать выводы об их эффективности?
- Давай агрегируем сумму для каждого уникального значения столбца ‘A’, выведем топ-10 результатов в таблицу и повторим процедуру для столбца ‘B’.
- Опиши график, который мы получили в пункте 3, сделай выводы и сформируй конструктивные предложения по оптимизации бизнес-процесса.
И так далее...
В данном подходе генеративная нейросеть может одновременно выступать как начинающий аналитик, выполняющий за вас рутинную работу по написанию кода, построению графиков и их описанию; так и в качестве опытного специалиста, предлагающего идеи для обработки данных, выдвигающего гипотезы на их основании, а также интерпретирующего результаты для более легкого восприятия и трансляции принимающей стороне.
Заключение
Как бы ни хотелось найти волшебную таблетку для уничтожения исследовательской рутины в лице генеративных нейросетей, пока это невозможно. Однако снижение количества ручной работы с кодом, поиск идей и гипотез для анализа, автоматизация построения графиков и их описания для дальнейшей презентации уже доступны. Я не рекламирую конкретные решения, в этой статье я просто поделился опытом, который помог мне сэкономить десятки часов. Надеюсь, что-то из этого материала вдохновит вас на изучение новых инструментов и сбережет время, которое вы сможете уделить своему профессиональному развитию — в сферах, которые помогут угнаться за невозможными темпами технологического прогресса.


Мы в соцсетях: